
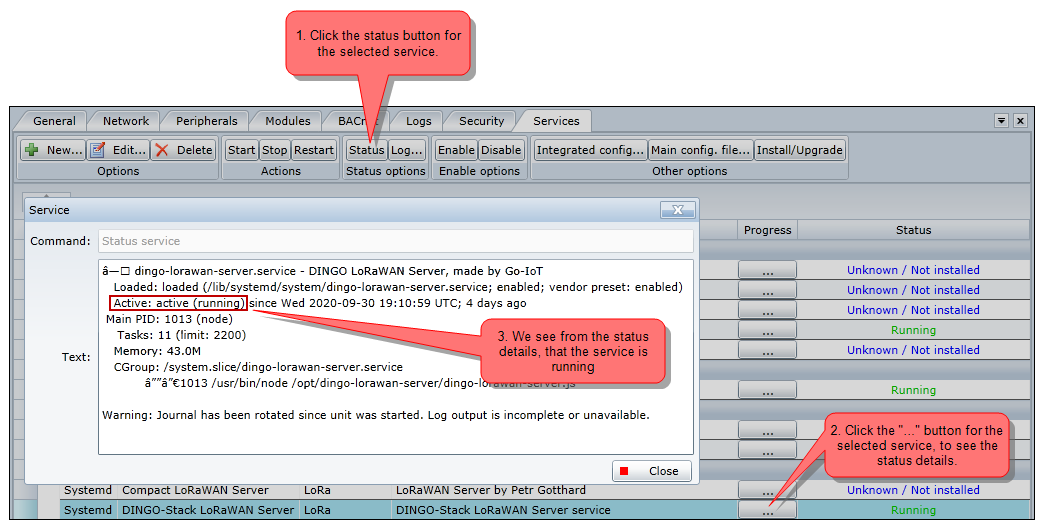
Troubleshoot service
If a service is not functioning as it should, then the first thing to check out, is its status. The status message shows if the service is running or not . It can also give detail information that can lead to an answer.
Note:
Some services will be restarted automatically on failure. This can be confusing when requesting the status. One second it shows Running , later it shows Dead and even later it shows Running again.
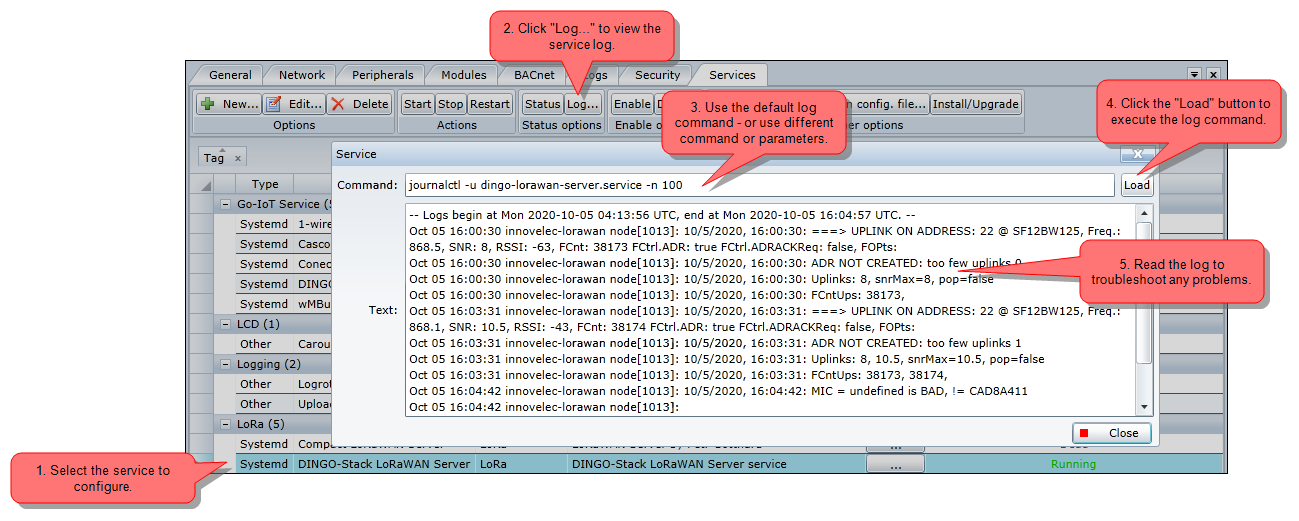
The best way to troubleshoot the service is by reading the log. The log can be read by clicking the "Log..." button.
The default log command, is the one that has been defined in the properties of the service.
Note:
If the problem is found in the main configuration file or the integrated configuration, then remember to restart the service after saving changes.
What follows are examples of commands to use, when reading logs.
This command is used with Systemd services.
Example: journalctl -u dingo-lorawan-server.service -n 100
This will read the last 100 lines for the Systemd-service called: dingo-lorawan-server.service
Here are the options for the journalctl command:
journalctl [OPTIONS...] [MATCHES...]
Query the journal.
Options:
| --system | Show the system journal | |
| --user | Show the user journal for the current user | |
| -M | --machine=CONTAINER | Operate on local container |
| -S | --since=DATE | Show entries not older than the specified date |
| -U | --until=DATE | Show entries not newer than the specified date |
| -c | --cursor=CURSOR | Show entries starting at the specified cursor |
| --after-cursor=CURSOR | Show entries after the specified cursor | |
| --show-cursor | Print the cursor after all the entries | |
| -b | --boot[=ID] | Show current boot or the specified boot |
| --list-boots | Show terse information about recorded boots | |
| -k | --dmesg | Show kernel message log from the current boot |
| -u | --unit=UNIT | Show logs from the specified unit |
| --user-unit=UNIT | Show logs from the specified user unit | |
| -t | --identifier=STRING | Show entries with the specified syslog identifier |
| -p | --priority=RANGE | Show entries with the specified priority |
| -g | --grep=PATTERN | Show entries with MESSAGE matching PATTERN |
| --case-sensitive[=BOOL] | Force case sensitive or insenstive matching | |
| -e | --pager-end | Immediately jump to the end in the pager |
| -f | --follow | Follow the journal |
| -n | --lines[=INTEGER] | Number of journal entries to show |
| --no-tail | Show all lines, even in follow mode | |
| -r | --reverse | Show the newest entries first |
| -o | --output=STRING |
Change journal output mode (short, short-precise, short-iso, short-iso-precise, short-full, short-monotonic, short-unix, verbose, export, json, json-pretty, json-sse, json-seq, cat, with-unit) |
| --output-fields=LIST | Select fields to print in verbose/export/json modes | |
| --utc | Express time in Coordinated Universal Time (UTC) | |
| -x | --catalog | Add message explanations where available |
| --no-full | Ellipsize fields | |
| -a | --all | Show all fields, including long and unprintable |
| -q | --quiet | Do not show info messages and privilege warning |
| --no-pager | Do not pipe output into a pager | |
| --no-hostname | Suppress output of hostname field | |
| -m | --merge | Show entries from all available journals |
| -D | --directory=PATH | Show journal files from directory |
| --file=PATH | Show journal file | |
| --root=ROOT | Operate on files below a root directory | |
| --interval=TIME | Time interval for changing the FSS sealing key | |
| --verify-key=KEY | Specify FSS verification key | |
| --force | Override of the FSS key pair with --setup-keys |
Commands:
| -h | --help | Show this help text |
| --version | Show package version | |
| -N | --fields | List all field names currently used |
| -F | --field=FIELD | List all values that a specified field takes |
| --disk-usage | Show total disk usage of all journal files | |
| --vacuum-size=BYTES | Reduce disk usage below specified size | |
| --vacuum-files=INT | Leave only the specified number of journal files | |
| --vacuum-time=TIME | Remove journal files older than specified time | |
| --verify | Verify journal file consistency | |
| --sync | Synchronize unwritten journal messages to disk | |
| --flush | Flush all journal data from /run into /var | |
| --rotate | Request immediate rotation of the journal files | |
| --header | Show journal header information | |
| --list-catalog | Show all message IDs in the catalog | |
| --dump-catalog | Show entries in the message catalog | |
| --update-catalog | Update the message catalog database | |
| --setup-keys | Generate a new FSS key pair |
This command is used for reading log- and textfiles.
Example: tail --lines 10 /opt/GoIoT/DinGo/dingo.log
This will read the last 10 lines from the DINGO-Stack log.
Here are the options for the tail command:
Usage: tail [OPTION]... [FILE]...
Print the last 10 lines of each FILE to standard output.
With more than one FILE, precede each with a header giving the file name.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
| -c | --bytes=[+]NUM |
output the last NUM bytes; or use -c +NUM to output starting with byte NUM of each file |
| -f | --follow[={name|descriptor}] |
output appended data as the file grows; an absent option argument means 'descriptor' |
| -F | same as --follow=name --retry | |
| -n | --lines=[+]NUM |
output the last NUM lines, instead of the last 10; or use -n +NUM to output starting with line NUM |
| --max-unchanged-stats=N |
with --follow=name, reopen a FILE which has not changed size after N (default 5) iterations to see if it has been unlinked or renamed (this is the usual case of rotated log files); with inotify, this option is rarely useful |
|
| --pid=PID | with -f, terminate after process ID, PID dies | |
| -q | --quiet | --silent never output headers giving file names |
| --retry | keep trying to open a file if it is inaccessible | |
| -s | --sleep-interval=N |
with -f, sleep for approximately N seconds (default 1.0) between iterations; with inotify and --pid=P, check process P at least once every N seconds |
| -v | --verbose | always output headers giving file names |
| -z | --zero-terminated | line delimiter is NUL, not newline |
| --help | display this help and exit | |
| --version | output version information and exit |
NUM may have a multiplier suffix:
b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024,
GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y.
With --follow (-f), tail defaults to following the file descriptor, which means that even if a tail'ed file is renamed, tail will continue to track
its end. This default behavior is not desirable when you really want to track the actual name of the file, not the file descriptor (e.g., log
rotation). Use --follow=name in that case. That causes tail to track the named file in a way that accommodates renaming, removal and creation.
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Full documentation at: <https://www.gnu.org/software/coreutils/tail>
or available locally via: info '(coreutils) tail invocation'
This command is used for reading log- and textfiles.
Example: cat /var/log/messages
This will read the lines from a log on the Linux system.
Here are the options for the cat command:
Usage: cat [OPTION]... [FILE]...
Concatenate FILE(s) to standard output.
With no FILE, or when FILE is -, read standard input.
| -A | --show-all | equivalent to -vET |
| -b | --number-nonblank | number nonempty output lines, overrides -n |
| -e | equivalent to -vE | |
| -E | --show-ends | display $ at end of each line |
| -n | --number | number all output lines |
| -s | --squeeze-blank | suppress repeated empty output lines |
| -t | equivalent to -vT | |
| -T | --show-tabs | display TAB characters as ^I |
| -u | (ignored) | |
| -v | --show-nonprinting | use ^ and M- notation, except for LFD and TAB |
| --help | display this help and exit | |
| --version | output version information and exit |
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Full documentation at: <https://www.gnu.org/software/coreutils/cat>
or available locally via: info '(coreutils) cat invocation'
This command is used for reading compressed log- and textfiles.
Example: zcat /var/log/messages.2.gz
This will read the lines from a compressed log on the Linux system.
Here are the options for the zcat command:
Usage: /bin/zcat [OPTION]... [FILE]...
Uncompress FILEs to standard output.
| -f | --force | force; read compressed data even from a terminal |
| -l | --list | list compressed file contents |
| -q | --quiet | suppress all warnings |
| -r | --recursive | operate recursively on directories |
| -S | --suffix=SUF | use suffix SUF on compressed files |
| --synchronous | synchronous output (safer if system crashes, but slower) | |
| -t | --test | test compressed file integrity |
| -v | --verbose | verbose mode |
| --help | display this help and exit | |
| --version | display version information and exit |
With no FILE, or when FILE is -, read standard input.
This command is used to search for patterns in log- and textfiles. This command can be used together with other commands.
Example: cat /var/log/messages | grep -i 'usb'
This will read the lines from a log on the Linux system and then only show lines that contain "usb", where the case (upper or lower case characters) is ignored.
Here are the options for the grep command:
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
Regexp selection and interpretation:
| -E | --extended-regexp | PATTERN is an extended regular expression (ERE) |
| -F | --fixed-strings | PATTERN is a set of newline-separated strings |
| -G | --basic-regexp | PATTERN is a basic regular expression (BRE) |
| -P | --perl-regexp PATTERN | is a Perl regular expression |
| -e | --regexp=PATTERN | use PATTERN for matching |
| -f | --file=FILE | obtain PATTERN from FILE |
| -i | --ignore-case | ignore case distinctions |
| -w | --word-regexp | force PATTERN to match only whole words |
| -x | --line-regexp | force PATTERN to match only whole lines |
| -z | --null-data | a data line ends in 0 byte, not newline |
Miscellaneous:
| -s | --no-messages | suppress error messages |
| -v | --invert-match | select non-matching lines |
| -V | --version display | version information and exit |
| --help | display this help text and exit |
Output control:
| -m | --max-count=NUM | stop after NUM matches |
| -b | --byte-offset | print the byte offset with output lines |
| -n | --line-number | print line number with output lines |
| --line-buffered | flush output on every line | |
| -H | --with-filename | print the file name for each match |
| -h | --no-filename | suppress the file name prefix on output |
| --label=LABEL | use LABEL as the standard input file name prefix | |
| -o | --only-matching | show only the part of a line matching PATTERN |
| -q | --quiet | --silent suppress all normal output |
| --binary-files=TYPE |
assume that binary files are TYPE; TYPE is 'binary', 'text', or 'without-match' |
|
| -a | --text | equivalent to --binary-files=text |
| -I | equivalent to --binary-files=without-match | |
| -d | --directories=ACTION |
how to handle directories; ACTION is 'read', 'recurse', or 'skip' |
| -D | --devices=ACTION |
how to handle devices, FIFOs and sockets; ACTION is 'read' or 'skip' |
| -r | --recursive | like --directories=recurse |
| -R | --dereference-recursive | likewise, but follow all symlinks |
| --include=FILE_PATTERN | search only files that match FILE_PATTERN | |
| --exclude=FILE_PATTERN | skip files and directories matching FILE_PATTERN | |
| --exclude-from=FILE | skip files matching any file pattern from FILE | |
| --exclude-dir=PATTERN | directories that match PATTERN will be skipped. | |
| -L | --files-without-match | print only names of FILEs containing no match |
| -l | --files-with-matches | print only names of FILEs containing matches |
| -c | --count | print only a count of matching lines per FILE |
| -T | --initial-tab | make tabs line up (if needed) |
| -Z | --null | print 0 byte after FILE name |
Context control:
| -B | --before-context=NUM | print NUM lines of leading context |
| -A | --after-context=NUM | print NUM lines of trailing context |
| -C | --context=NUM | print NUM lines of output context |
| -NUM | same as --context=NUM | |
| --color[=WHEN], | ||
| --colour[=WHEN] |
use markers to highlight the matching strings; WHEN is 'always', 'never', or 'auto' |
|
| -U | --binary | do not strip CR characters at EOL (MSDOS/Windows) |
| -u | --unix-byte-offsets |
report offsets as if CRs were not there (MSDOS/Windows) |
'egrep' means 'grep -E'. 'fgrep' means 'grep -F'.
Direct invocation as either 'egrep' or 'fgrep' is deprecated.
When FILE is -, read standard input. With no FILE, read . if a command-line -r is given, - otherwise. If fewer than two FILEs are given, assume -h.
Exit status is 0 if any line is selected, 1 otherwise; if any error occurs and -q is not given, the exit status is 2.
GNU grep home page: <http://www.gnu.org/software/grep/>
General help using GNU software: <http://www.gnu.org/gethelp/>